
Documentation
Common Data Model (CDM)
Convert Database to CDM (ETL)
Tool Specific Documentation
Common Data Model (CDM)
Convert Database to CDM (ETL)
Tool Specific Documentation
This is an old revision of the document!
![]()
Usagi is a software tool created by the Observational Health Data Sciences and Informatics (OHDSI) team and is used to help in the process of mapping codes from a source system into the standard terminologies stored in the Observational Medical Outcomes Partnership (OMOP) Vocabulary (http://www.ohdsi.org/data-standardization/vocabulary-resources/). The word Usagi is Japanese for rabbit and was named after the first mapping exercise it was used for; mapping source codes used in a Japanese dataset into OMOP Vocabulary concepts.
Mapping source codes into the OMOP Vocabulary is valuable for two main reasons:
Source codes that needs mapping are loaded into the Usagi (if the codes are not in English additional translations columns are needed). A term similarity approach is used to connect source codes to Vocabulary concepts. However these code connections need to be manually reviewed and Usagi provides an interface to facilitate that.
Usagi currently does not currently translate non-English codes to English. We suggest using Google Translate (https://translate.google.com/). You can paste an entire column of non-English terms into Google Translate, and it will return that same column translated to English.
Usagi will only propose concepts that are marked as standard concepts in the Vocabulary.
The typical sequence for using this software is:
All source code and installation instructions are available on Usagi’s GitHub site: https://github.com/OHDSI/Usagi
Any bugs/issues/enhancements should be posted to the GitHub repository: https://github.com/OHDSI/Usagi/issues
Any questions/comments/feedback/discussion can be posted on the OHDSI Developer Forum: http://forums.ohdsi.org/c/developers
Export source codes from source system into a CSV or Excel (.xlsx) file. This should at least have columns containing the source code and an English source code description, however additional information about codes can be brought over as well (e.g. dose unit, or the description in the original language if translated). In addition to information about the source codes, the frequency of the code should preferably also be brought over, since this can help prioritize which codes should receive the most effort in mapping (e.g. you can have 1,000 source codes but only 100 are truly used within the system). If any source code information needs translating to English, use Google Translate to do that.
Note: source code extracts should be broken out by domain (i.e. drugs, procedures, conditions, observations) and not lumped into one large file.
Source codes are loaded into Usagi from the File –> Import codes menu. From here an “Import codes …” will display as seen in Figure 1.
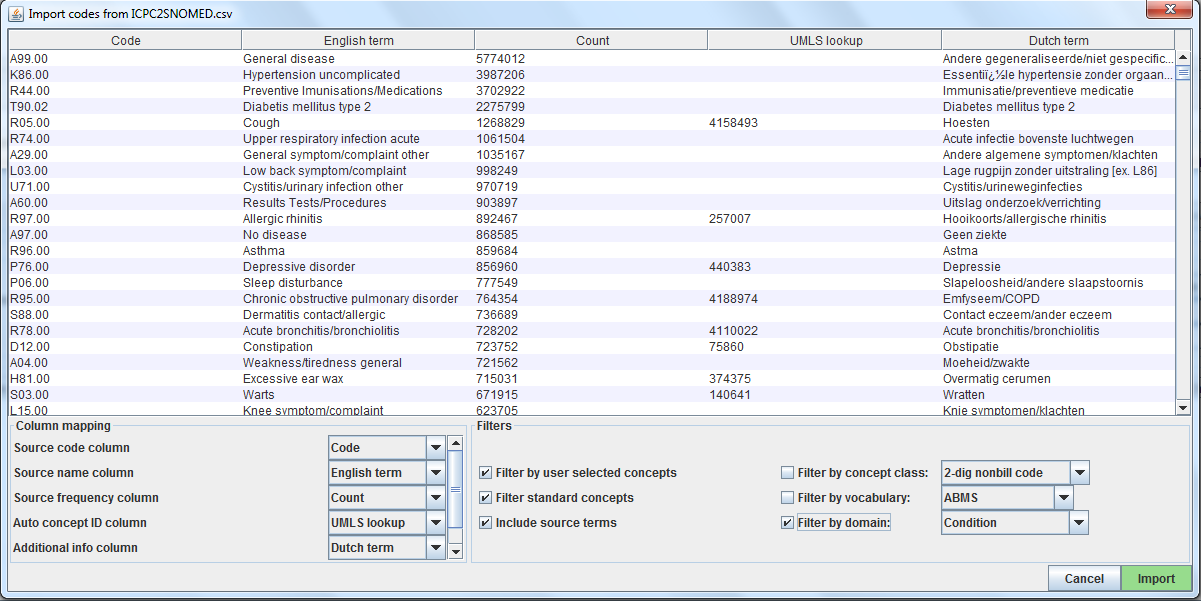 Figure 1: Usagi Source Code Input Screen
Figure 1: Usagi Source Code Input Screen
In Figure 1, the source code terms were in Dutch and were also translated into English. Usagi will leverage the English translations to map to the standard vocabulary (SNOMED in this case).
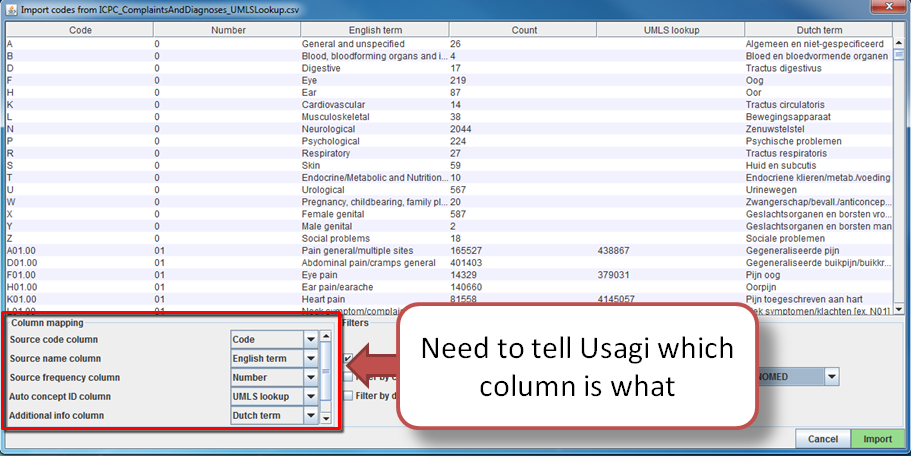 Figure 2: Telling Usagi how to Read Input File
Figure 2: Telling Usagi how to Read Input File
Seen in Figure 2, the Column mapping section is where you define for Usagi how to use the imported CSV. If you mouse hover over the drop downs, a pop-up will appear defining each column. Usagi will not use the Additional info column(s) as information to associate source codes to Vocabulary concept codes; however this additional information may help the individual reviewing the source code mapping and should be included.
Finally you can tell Usagi what OMOP Vocabulary terminologies you plan to map into. For example, in Figure 3, the user is mapping the source codes to the SNOMED standard terminology the OMOP Vocabulary. Hover your mouse over the different filters for additional information about the filter.
One special filter is Filter by automatically selected concepts. If there is information that you can use to restrict the search, you can do so by providing a list of CONCEPT_IDs in the column indicated in the Auto concept ID column (semicolon-delimited). For example, in the case of drugs there might be a mapping available to ATC codes. Even though an ATC code does not uniquely identify a single RxNorm drug code, it does help limit the search space to only those concepts that fall under the ATC code in the Vocabulary. By providing this list of CONCEPT_IDs in the Auto concept ID column, and turning on Filter by automatically selected concepts, Usagi will make use of this information. In the example above, we used a partial mapping derived from UMLS to restrict Usagi to this mapping when available.
 Figure 3: Defining OMOP Vocabulary Terminology Usagi Should Plan to Map to
Figure 3: Defining OMOP Vocabulary Terminology Usagi Should Plan to Map to
Once all your settings are finalized, click the “Import” button to import the file. The file import will take a few minutes as it is running the term similarity algorithm to map source codes.
Once you have set up your input file of source codes, the mapping process begins.
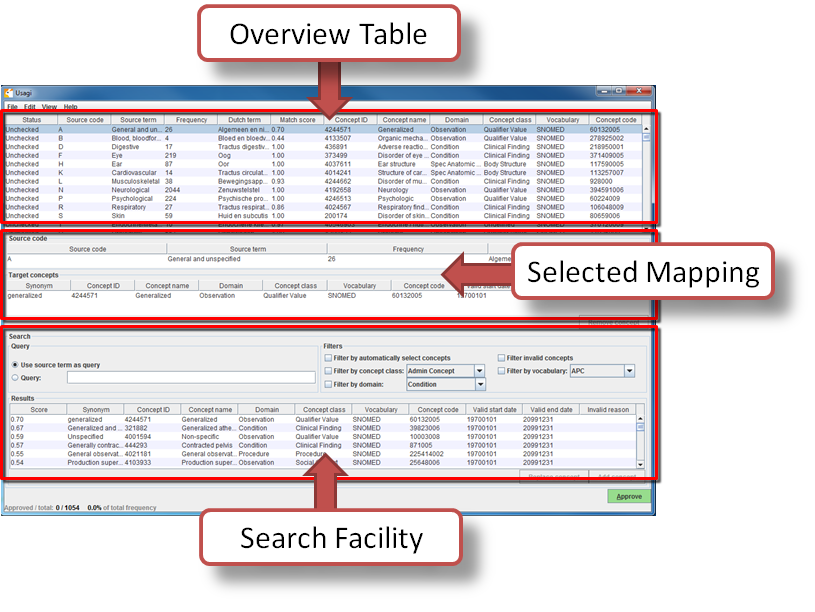 Figure 4: Usagi Matching Screen
Figure 4: Usagi Matching Screen
In Figure 4, you see the Usagi screen is made up of 3 main sections: an overview table, the selected mapping section, and place to perform searches.
Note that in any of the tables, you can right-click to select the columns that are shown or hidden to reduce the visual complexity.
In the Overview Table, Usagi tries to make suggested related concepts to the source codes it was provided. In the example in Figure 4, the English names of Dutch condition codes were mapped to SNOMED conditions; Usagi searches for concept names and synonyms (taken from UMLS) based on whatever English text it is given. If Usagi is unable to make a mapping, it will map to the CONCEPT_ID = 0. If you noticed all the suggested mappings are 0 there may be an issue with the initial index generated by Usagi, use the Help –> rebuild index option to rebuild the index.
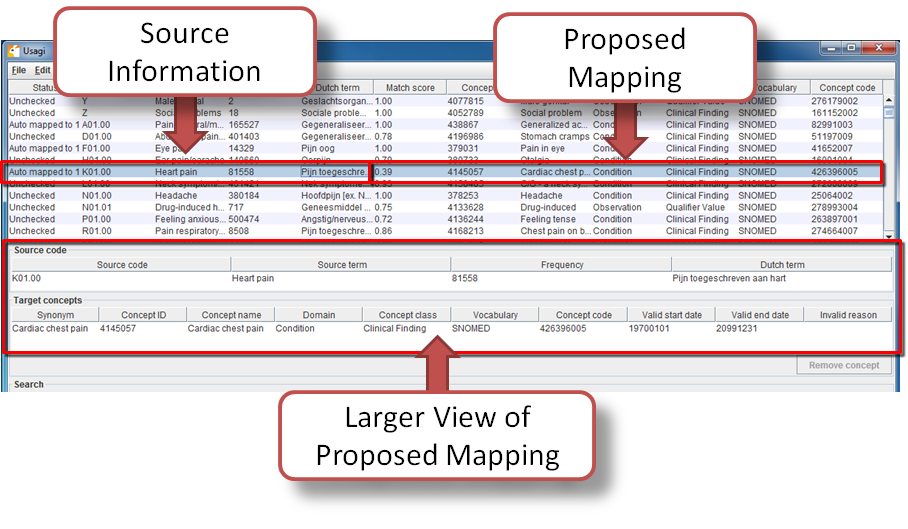 Figure 5: Reviewing an Usagi Match
Figure 5: Reviewing an Usagi Match
It is suggested that someone with experience with coding systems help map source codes to their associated standard vocabulary. That individual will work through code by code in the Overview Table to either accept the mapping Usagi has suggested or choose a new mapping. For example in Figure 5 we see that the Dutch term “Pijn toegeschreven aan hart” which was translated to the English term “Heart pain”. Usagi used “Heart pain” and mapped it to the OMOP Vocabulary concept of “4145057-Cardiac chest pain”. There was a matching score of 0.39 associated to this matched pair (matching scores are typically 0 to 1 with 1 being a confident match), a score of 0.39 signifies that Usagi is not very sure of how well it has mapped this Dutch code to SNOMED. Let us say in this case, we are okay with this mapping, we can approve it by hitting the green “Approve” button in the bottom right hand portion of the screen.
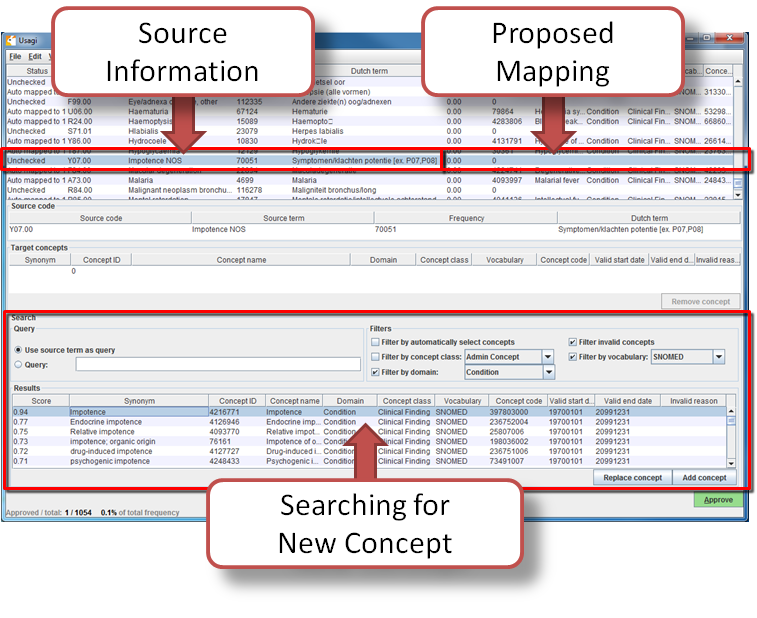 Figure 6: Searching for a New Concept
Figure 6: Searching for a New Concept
There will be cases where Usagi suggests a map and the user will be left to either try to find a better mapping or set the map to no concept (CONCEPT_ID = 0). In the example given in Figure 6, we see for the Dutch Term “Symptomen/klachten potentie [ex. P07,P08]”, which was translated to “Impotence NOS”. Usagi was unable to make a proper map because the UMLS derived mapping used a non-valid concept, and therefore mapped it to CONCEPT_ID = 0. In the Search Facility, we could search for other concepts using either the actual term itself or a search box query.
When using the manual search box, there are some things to keep in mind: Usagi’s search algorithm is based on complete words, so the search ‘cardi’ will not find terms containing the word ‘cardiac’. To use partial words you can insert a wildcard ‘*’, so for example ‘cardi*’ will find both ‘cardiac’ and ‘cardiology’. Usagi is able to deal with plurals, so ‘child’ will also find ‘children’. You can use simple boolean logic in the search box, for example ‘cardiac AND arrest’ will find only those terms containing both words, whereas ‘cardiac OR heart’ will find all terms containing one or both of the two words.
To continue our example, suppose we used the search term “Impotence NOS” to see if we could find a better mapping. On the right of the Query section of the Search Facility, there is a Filters section, this provides options to trim down the results from the OMOP Vocabulary when searching for the search term. In this case we know we want to only find SNOMED terms, we only want valid concepts, and we are looking for concepts in the CONDITION domain.
When we apply these search criteria we find “4216771-Impotence” and feel this may be an appropriate Vocabulary concept to map to our Dutch code, in order to do that we can hit the “Replace concept”, which you will see the Selected Source Code section update, followed by the “Approved” button. There is also an “Add concept” button, this allows for multiple standardized Vocabulary concepts to map to one source code (e.g. some source codes may bundle multiple diseases together while the standardized vocabulary may not).
When you import your source codes there is an option to add information about “Auto concept ID column”. If there is information already known that will allow you to map your source data to a CONCEPT_ID, you can include that in the file you upload into Usagi. Once loaded, the Overview Table will list these codes with a status of “Auto mapped to 1” if only one CONCEPT_ID was provided, or just “Auto mapped” if there were more. You still will be required to approve these auto mappings using the “Approve” button, or if you really trust the underlying information, you can sort by status, select all codes with status ‘Auto mapped to 1”, and click Edit –> Approve selected.
Continue to move through this process, code by code, until all codes have been checked. In the list of source codes at the top of the screen, by selecting the column heading you can sort the codes. Often we suggest going from the highest frequency codes to the lowest (often you will find the two set of codes cover most of the data).
Best Practices:
Once you have created your map within USAGI, the best way to use it moving forward is to export it and append it to the OMOP Vocabulary SOURCE_TO_CONCEPT_MAP table.
To export your mappings go to File –> Export source_to_concept_map. A pop-up will appear asking you which SOURCE_VOCABULARY_ID you would like to use, type in a number (it is suggested to make the ID greater than 100 so that it can be easily identified as a non-OMOP vocabulary). Usagi will use this number as the SOURCE_VOCABULARY_ID which will allow you to identify your specific mapping in the SOURCE_TO_CONCEPT_MAP table. For example, if you SOURCE_VOCABULARY_ID = 200 then when mapping to TARGET_CONCEPT_IDs you can filter the SOURCE_TO_CONCEPT_MAP table where SOURCE_VOCABULARY_ID = 200.
After selecting the SOURCE_VOCABULARY_ID, you give your export CSV a name and save to location. The export CSV structure is in that of the SOURCE_TO_CONCEPT_MAP table. This mapping could be appended to the OMOP Vocabulary’s SOURCE_TO_CONCEPT_MAP table. It would also make sense to append a single row to the VOCABULARY table defining the SOURCE_VOCABULARY_ID you defined in the step above. Finally, it is important to note that only mappings with the “Approved” status will be exported into the CSV file; the mapping needs to be completed in USAGI in order to export it.
Once you have loaded a source code file to begin mapping using Usagi you can save this working file using File –> Save or File –> Save as. Once you save the file you can close Usagi at any time and come back to your file later by using File –> Open.
The Edit menu provides options around approving. Approved selected is helpful if you want to approve many codes at one time.
The View –> Concept information is designed to help a user get more information about a concept they are reviewing however this feature is currently still experimental.
The Help menu will get you to About Usagi will point you to informative links or Rebuild Index which provides you the option to rebuild the index off the OMOP Vocabulary. Typically you will rebuild an index if your current index has a flaw or you have received an updated version of the OMOP Vocabulary.